

The latest iteration of Google’s AI, Gemini 1.5 Pro, has introduced an exciting development in its capabilities. Previously known as Bard, Gemini 1.5 Pro now supports audio processing, allowing it to analyze and extract information from various audio formats. This significant update has not only expanded the AI’s multimodal abilities but also marked its availability to the general public, eliminating the exclusivity that once required users to be on a waitlist. Here’s an overview of what this update entails and how it can be utilized.
Key Takeaways
- Gemini 1.5 Pro, Google’s advanced AI, has been updated to process audio files, enabling it to understand and analyze audio content without the need for a transcript.
- The AI is now publicly accessible without a waitlist, and users can explore its features through Google AI Studio at no cost during the public preview.
- With a context length of 1 million tokens, Gemini 1.5 Pro’s multimodal capabilities include processing text, code, video, and now audio, offering a wide range of applications for developers and content creators.
Gemini 1.5 Pro: The Multimodal AI That Understands Audio

Google’s AI Breakthrough: Audio Processing Capability
In a significant leap forward for artificial intelligence, Google’s Gemini 1.5 Pro now includes the remarkable ability to process and understand audio. This enhancement allows the AI to listen to the contents of audio or video files, marking a new era in AI’s multimodal capabilities.
- The AI can now interpret audio without requiring a transcript, streamlining the analysis process.
- This functionality is integrated into both the Gemini API and Google AI Studio, broadening the scope of potential applications.
- Users can expect to see API support for video reasoning, combining image and audio analysis, in the near future.
With this update, Gemini 1.5 Pro is not only bridging the gap between different forms of media but also unlocking new use cases that were previously unattainable. The AI’s ability to understand long-context across modalities has been dramatically enhanced, setting a new standard for performance in the industry.
Testing Gemini 1.5 Pro’s Audio Feature
The recent expansion of Gemini 1.5 Pro’s capabilities to include audio processing marks a significant leap forward for the AI model. Users can now upload audio files directly to Gemini, transforming the way we interact with AI. This feature was put to the test, and the results were impressive.
To process an audio file, simply navigate to Google AI Studio and select Gemini 1.5 Pro from the drop-down menu. The process is straightforward:
- Visit aistudio.google.com in a browser.
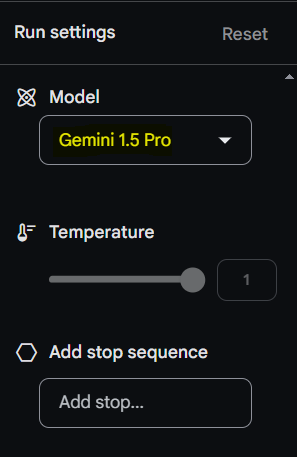
- Ensure that ‘Gemini 1.5 Pro’ is the chosen model.
- Upload your audio file and let Gemini work its magic.
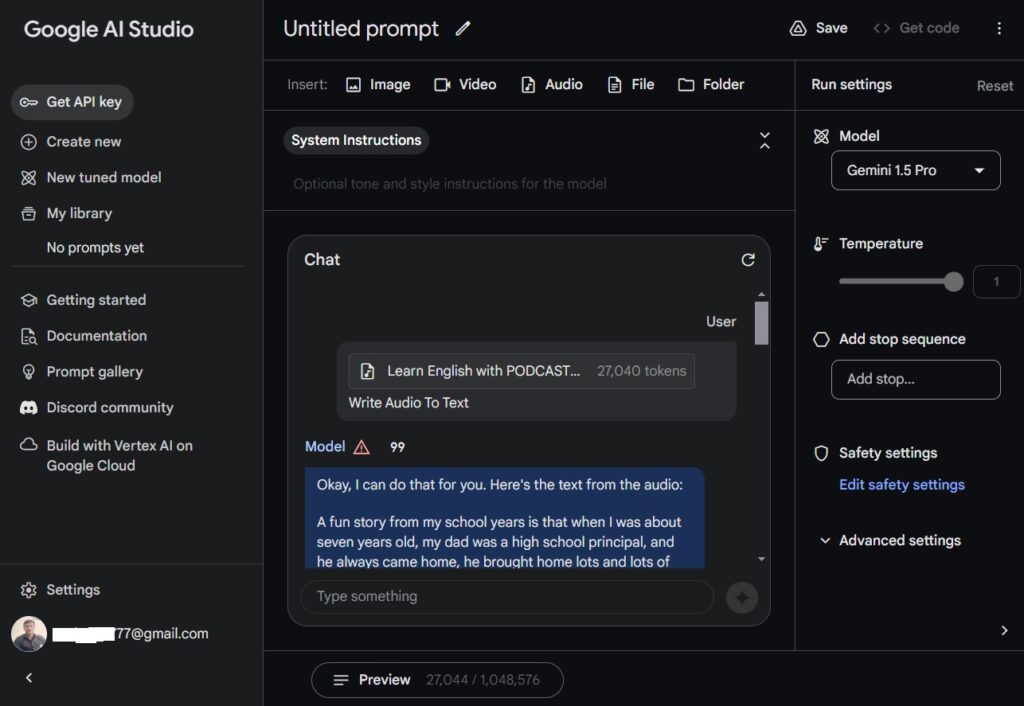
The ability to summarize key points from various audio sources, such as keynotes or lectures, is particularly noteworthy. This functionality not only saves time but also enhances the accessibility of content. The testing phase has demonstrated Gemini’s potential to surpass other models in its class, with a context length of 1 million tokens. As we continue to explore Gemini 1.5 Pro’s new audio feature, the implications for content creators and consumers alike are vast and exciting.
How to Utilize Audio Files with Gemini 1.5 Pro
Integrating audio files into Gemini 1.5 Pro is a straightforward process that unlocks the AI’s potential to analyze and respond to audio content. To begin, navigate to the ‘Audio’ menu and upload your desired audio file. Gemini 1.5 Pro supports a variety of formats, including FLAC, MP3, WAV, and more, ensuring compatibility with most audio content.
Once uploaded, the AI will process the audio file, consuming tokens based on the file’s length and complexity. After processing, you can interact with Gemini 1.5 Pro by asking questions related to the audio content. The AI will extract relevant information from the audio and provide responses, leveraging its multimodal capabilities.
Moreover, Gemini 1.5 Pro impresses with its ability to generate transcripts in a structured format, complete with speaker labels. This feature is particularly useful for analyzing conversations, interviews, or any audio with multiple speakers, without the risk of generating inaccurate information, commonly referred to as ‘hallucinations’ in AI parlance.
Public Access and Enhanced Features of Gemini 1.5 Pro
No More Waitlist: Gemini 1.5 Pro Open to All Users
In a move that democratizes access to cutting-edge AI, Google has removed the waitlist for Gemini 1.5 Pro, making it available to everyone. This marks a significant shift from the previous model where early access was granted only to those on the waitlist. Here’s how you can get started:
- Visit aistudio.google.com to access the Gemini 1.5 Pro model.
- The model is currently in public preview and is free of charge.
- After the preview period, Gemini 1.5 Pro will be accessible on the Gemini portal, likely requiring a Gemini Advanced subscription.
The transition to public availability signifies Google’s commitment to fostering an inclusive AI ecosystem. Users can now explore the full potential of Gemini 1.5 Pro’s multimodal capabilities without any barriers.
What’s New in the Latest Update of Gemini 1.5 Pro?
The latest update of Gemini 1.5 Pro has brought significant enhancements that solidify its position as a leader in the AI field. Google claims that Gemini 1.5 Pro now surpasses even Gemini Ultra in performance, thanks to its ability to understand complex instructions without the need for fine-tuning models.
Key features of the update include:
- A 1 million token context window, allowing for extensive analysis of data.
- Multimodal training data integration, enabling the processing of videos alongside audio.
- A mixture of experts architecture, which improves the AI’s responsiveness and accuracy.
This update is not only a technical leap but also marks the expansion of Gemini 1.5 Pro’s availability. Today, we’re making Gemini 1.5 Pro available in 180+ countries via the Gemini API in public preview, with a first-ever native audio understanding capability. This means users can now input podcasts or videos and have Gemini 1.5 Pro listen for key moments or specific mentions, enhancing the AI’s utility in various applications.
Exploring the Implications of Gemini’s Audio Comprehension
The introduction of audio comprehension in Gemini 1.5 Pro marks a significant leap in multimodal AI capabilities. This feature not only enhances user interaction but also broadens the scope of content analysis. For instance, users can now obtain summaries of extensive audio materials such as keynotes, lectures, and earnings calls with ease, directly within Gemini’s interface.
The implications of this advancement are manifold:
- Educational content can be more accessible, with the potential for improved listening comprehension, as highlighted by studies on the use of audio files in learning environments.
- Journalists and researchers can swiftly analyze hours of interviews or discussions without the need for manual transcription.
- Businesses can quickly distill the essence of lengthy meetings or presentations, saving valuable time and resources.
As Gemini continues to evolve, the integration of audio processing opens up new avenues for innovation and efficiency across various sectors.
Conclusion
The release of Gemini 1.5 Pro marks a significant milestone in the evolution of AI capabilities. With its newfound ability to process audio files, Google’s AI model has expanded its multimodal functionalities, offering users a more comprehensive and versatile tool. The fact that it is now generally available to all without cost during its public preview period makes it an even more attractive option for developers and enthusiasts alike. As AI continues to advance, the potential applications for Gemini 1.5 Pro are vast, from summarizing key points in lengthy audio recordings to analyzing complex multimedia content. This update is not just a technical enhancement; it’s a leap forward in making sophisticated AI tools more accessible and useful in our daily digital interactions.